在当今世界,我们有大量的非结构化数据/信息(主要是网络数据)可以免费获得。有时这些免费提供的数据易于阅读,有时则不然。无论您的数据如何提供,网页抓取都是一个有用的工具,可以将非结构化数据转换为更易于阅读和分析的结构化数据。换句话说,网页抓取是一种收集、组织和分析这种大量数据的方式。因此,让我们首先了解一下什么是网页抓取。
Beautiful Soup介绍
Beautiful Soup 是一个Python库,其名称来源于刘易斯·卡罗尔在《爱丽丝梦游仙境》中的同名诗篇。正如其名,Beautiful Soup 解析掉不需要的数据,并帮助组织和格式化混乱的网络数据,通过修正不良的HTML代码并以易于遍历的XML结构呈现给我们。
简而言之,Beautiful Soup 是一个允许我们从HTML和XML文档中提取数据的Python包。
HTML树结构
在我们查看Beautiful Soup提供的功能之前,让我们首先了解HTML树结构。
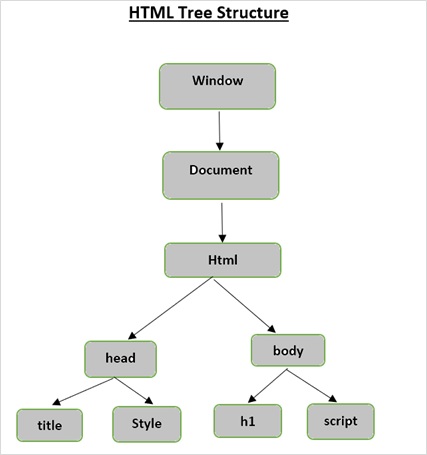
HTML树结构
文档树中的根元素是html,它可以有父元素、子元素和兄弟元素,并且这由它在树结构中的位置决定。要在HTML元素、属性和文本之间移动,您必须在树结构中的节点间移动。
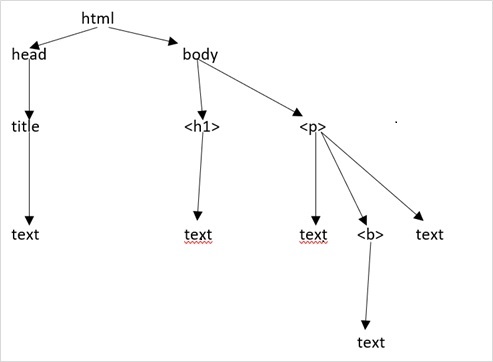
假设网页如下所示:

这转化为如下所示的HTML文档:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint 在线图书馆</h1>
<p><b>一切都是免费的</b></p>
</body>
</html>
这意味着对于上述HTML文档,我们有一个如下所示的HTML树结构: