语音是最基本的成人交流方式。语音处理的基本目标是提供人与机器之间的交互。
语音处理系统主要有三个任务:
首先,语音识别使机器能够捕捉我们所说的单词、短语和句子;
其次,自然语言处理让机器能够理解我们所说的内容;
第三,语音合成使机器能够发声。
本章的重点在于语音识别,即理解人类所说的单词的过程。记住,语音信号是通过麦克风捕捉的,然后必须被系统理解。
构建语音识别器
语音识别(Automatic Speech Recognition, ASR)是像机器人这样的 AI 项目的关注中心。没有 ASR,很难想象一个能与人类互动的认知机器人。然而,构建一个语音识别器并不容易。
开发语音识别系统的困难
开发高质量的语音识别系统确实是一个难题。语音识别技术的难度可以从多个维度来概括:
-
词汇表大小 —— 词汇表的大小影响了开发 ASR 的难易程度。请考虑以下不同大小的词汇表以更好地理解:
-
小规模词汇表包含 2-100 个单词,例如,在语音菜单系统中;
-
中等规模词汇表包含几百到几千个单词,例如,在数据库检索任务中;
-
大规模词汇表包含几万个单词,例如,在一般的听写任务中。
-
-
通道特性 —— 通道质量也是一个重要因素。例如,人类语音包含宽带宽和全频段,而电话语音则带宽带限且频段有限。注意后者更难处理。
-
说话模式 —— 开发 ASR 的难易程度还取决于说话模式,即语音是否为孤立词模式、连接词模式或连续语音模式。注意连续语音更难识别。
-
说话风格 —— 朗读的语音可能是正式风格,也可能是随意且对话式的。后者更难识别。
-
说话者依赖性 —— 语音可以是说话者依赖的、说话者自适应的或说话者独立的。说话者独立的最难构建。
-
噪声类型 —— 在开发 ASR 时,噪声是另一个要考虑的因素。信噪比可能在不同范围内,这取决于观察到的背景噪声较少还是较多:
-
-
如果信噪比介于 30dB 至 10dB 之间,则认为是中等 SNR;
-
-
背景噪声的类型,例如静态的、非人类的噪声、背景语音和其他说话者的串扰,也会增加问题的难度。
-
麦克风特性 —— 麦克风的质量可能是好的、一般的或低于平均水平的。此外,嘴与麦克风之间的距离也可能有所不同。这些因素也应被考虑在内。
尽管存在这些困难,研究人员仍然在语音的各个方面,如理解语音信号、说话者和识别口音等方面进行了大量工作。
为了构建一个语音识别器,你需要遵循以下步骤:
可视化音频信号 - 从文件中读取并处理
这是构建语音识别系统的第一步,因为它让你了解音频信号是如何构建的。处理音频信号的一些常见步骤如下:
录制
当你需要从文件中读取音频信号时,首先要使用麦克风录制它。
采样
当使用麦克风录音时,信号会以数字化的形式存储。但为了处理它们,机器需要它们以离散数值的形式。因此,应该在某个频率下进行采样并将信号转换成离散数值形式。选择较高的采样频率意味着当人类听到信号时,他们会感觉它是连续的音频信号。
示例
以下示例展示了一个逐步分析存储在文件中的音频信号的方法,使用 Python,音频信号的频率为 44,100 Hz。
导入必要的包,如下所示:
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
现在,读取存储的音频文件。它将返回两个值:采样频率和音频信号。提供音频文件的存储路径,如下所示:
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
显示音频信号的采样频率、信号的数据类型及其持续时间,使用以下命令:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')
此步骤涉及信号的标准化,如下所示:
audio_signal = audio_signal / np.power(2, 15)
在此步骤中,我们从信号中提取前 100 个值以进行可视化。使用以下命令:
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(audio_signal), 1) / float(frequency_sampling)
现在,使用以下命令可视化信号:
plt.plot(time_axis, audio_signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()
你将能够看到上述音频信号的输出图表和提取的数据,如下图所示:
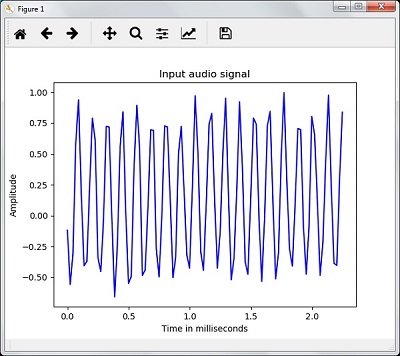
可视化音频信号
使用 Python 和人工智能进行语音识别
语音是最基本的成人交流方式。语音处理的基本目标是提供人与机器之间的交互。
语音处理系统主要有三个任务:
首先,语音识别允许机器捕获我们说出的单词、短语和句子;
其次,自然语言处理允许机器理解我们说的话;
最后,语音合成允许机器说话。
本章专注于语音识别,即理解我们说的单词的过程。请注意,语音信号是由麦克风捕获的,并由系统解释。
构建语音识别器
构建高质量的语音识别器非常具有挑战性。语音识别技术的复杂性可以从几个方面来描述:
尺寸较小的词汇量——词汇量的大小会影响建立 ASR 的难度。以下是几种不同的词汇量大小的例子,以便更好地理解:
-
小词汇量包括 2 到 100 个单词,例如在语音菜单系统中;
-
中等词汇量包括数百至数千个单词,例如在数据库检索任务中;
-
注意,词汇量越大,识别起来就越困难。
频道特征——频道质量也是重要的因素。例如,人类语音包含全频谱和高带宽,而电话语音仅包含有限频谱和低带宽。注意后一种情况更难以处理。
说话模式——构建 ASR 的难度还取决于说话模式,即语音是孤立词模式、连接词模式还是连续语音模式。注意连续语音更难识别。
说话风格——口语可能是正式的,也可能是随意的和对话式的。后者更难识别。
说话者依赖性——语音可以是说话者特定的、适应说话者的,也可以是说话者无关的。说话者无关的情况最困难。
噪音类型——在构建 ASR 时,还需要考虑噪音。声学环境中的信噪比可能有各种水平,具体取决于背景噪音的多少:
-
-
如果信噪比在 30 dB 到 10 dB 之间,则被认为是中等 SNR;
-
背景噪音的类型也很重要,比如静止的、非人类的噪音、背景语音以及其他说话人的干扰都会增加问题的复杂性。
麦克风特性——麦克风的质量可能好、一般或差。此外,嘴巴和麦克风之间的距离也可能不同。这些因素也应该考虑到识别系统中。
尽管存在这些挑战,研究人员仍在语音的不同方面投入了大量的精力,例如理解语音信号、说话人和口音识别。
要构建语音识别器,请按照以下步骤操作:
可视化音频信号——从文件中读取和处理
这是构建语音识别系统的第一步,因为这样可以帮助您了解音频信号如何构成。您可以采取以下常规步骤来处理音频信号:
录制
如果您打算从文件中读取音频信号,请先用麦克风记录下来。
采样
当用麦克风记录声音时,信号将以数字形式存储。但是为了让计算机能够处理它,需要将其转换为离散的数值形式。为此,需要以一定的频率进行采样,使得人类听起来像是连续的声音。
示例
下面的示例演示了如何逐步分析存储在文件中的音频信号,使用 Python,音频信号的频率为 44,100 Hz。
首先导入所需的包,如下所示:
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
接着,读取存储的音频文件。这将返回两个值:采样率和音频信号。请提供音频文件的路径,如下所示:
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
打印出音频信号的采样率、数据类型和持续时间,如下所示:
print('\nSignal shape:', audio_signal.shape)
print('Signal Datatype:', audio_signal.dtype)
print('Signal duration:', round(audio_signal.shape[0] /
float(frequency_sampling), 2), 'seconds')
在这个步骤中,对信号进行归一化,如下所示:
audio_signal = audio_signal / np.power(2, 15)
在这个步骤中,我们将从信号中提取前 100 个值来进行可视化。使用以下代码:
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(audio_signal), 1) / float(frequency_sampling)
现在,使用以下代码可视化信号:
plt.plot(time_axis, audio_signal, color='blue')
plt.xlabel('Time (milliseconds)')
plt.ylabel('Amplitude')
plt.title('Input audio signal')
plt.show()
您将看到上图所示的输出图形和提取的数据。
可视化音频信号
生成单音音频信号
你所见到的前两步对于了解信号很重要。现在,如果你想要生成带有预定义参数的音频信号,那么这一步将很有用。注意,这一步骤将会把音频信号保存在一个输出文件中。
生成单音音频信号
示例
在下面的示例中,我们将生成一个单音信号,并将其存储在一个文件中。为此,你需要按照以下步骤操作:
导入必要的包
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import write
提供输出文件路径
output_file = 'audio_signal_generated.wav'
设定参数
duration = 4
frequency_sampling = 44100
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.pi
生成音频信号
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * frequency_tone * t)
保存音频文件
signal_scaled = np.int16(audio_signal / np.max(np.abs(audio_signal)) * 32767)
write(output_file, frequency_sampling, signal_scaled)
提取前100个值用于绘图
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(audio_signal), 1) / float(frequency_sampling)
可视化生成的音频信号
plt.plot(time_axis, audio_signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()
你可以观察到如图所示的图表:
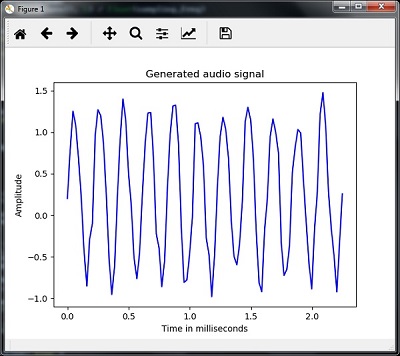
从语音中提取特征
这是构建语音识别器最重要的步骤之一,因为在将语音信号转换到频域之后,我们必须将其转换为可用的特征向量形式。我们可以使用不同的特征提取技术,如 MFCC、PLP、PLP-RASTA 等。
示例
在下面的示例中,我们将逐步使用 Python 和 MFCC 技术来从信号中提取特征。
导入必要的包
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank
读取存储的音频文件
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")
注意这里我们只取前15000个样本进行分析:
audio_signal = audio_signal[:15000]
使用 MFCC 技术提取 MFCC 特征
features_mfcc = mfcc(audio_signal, frequency_sampling)
打印 MFCC 参数
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])
绘制并可视化 MFCC 特征
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')
与滤波器组特征一起工作
提取滤波器组特征:
filterbank_features = logfbank(audio_signal, frequency_sampling)
打印滤波器组参数
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])
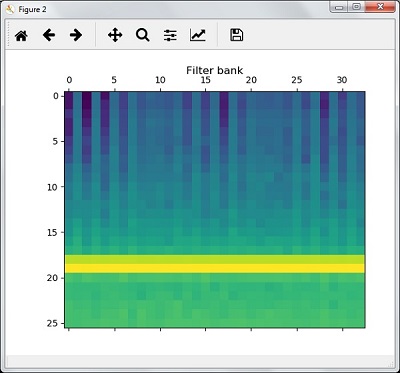
绘制并可视化滤波器组特征
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
根据以上步骤,你可以观察到以下输出:图1为 MFCC,图2为 滤波器组
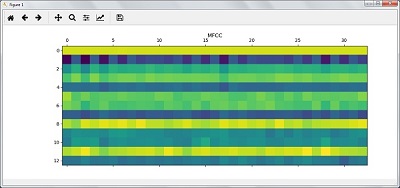
识别语音单词
语音识别意味着当人们说话时,机器能够理解它。在这里,我们使用 Python 中的 Google Speech API 来实现这一点。为此,我们需要安装以下包:
-
Pyaudio - 可以使用
pip install pyaudio 命令安装。
-
SpeechRecognition - 可以使用
pip install SpeechRecognition 命令安装。
-
Google-Speech-API - 可以使用
pip install google-api-python-client 命令安装。
示例
观察以下示例以了解如何识别语音单词:
导入必要的包
import speech_recognition as sr
创建对象
recording = sr.Recognizer()
使用麦克风模块输入语音
with sr.Microphone() as source:
recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)
Google API 识别语音并给出输出
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)
你可以看到以下输出:
Please Say Something:
You said:
例如,如果你说的是 "yoagoa.com",那么系统将正确地识别为:
yoagoa.com